
I’ve been getting my hands dirty with Machine Learning lately. I made this research on target encoding in ML and how it can improve or alter the model’s accuracy and I want to share it with you. Having a machine learning feature from a dataset that has too many categorical variations can make the ML model over complicated. For example unique fields like IDs or categories with too many possibilities (city names). One good option to still use these fields in a ML model is to aggregate and encode them. We will do this by using target encoding. Let’s see how that works in more detail.
This is a self made experiment, no external materials were used as inspiration.
What is Target Encoding
Target Encoding is a method to convert a categorical feature into the mean value of the target. The result is a new column and this will replace the original categorical feature when training the ML model.
Let’s see a simple example. We will follow a ML model to predict the city temperature based on some basic data which was collected over some time.
| city name | temperature (Y) |
|---|---|
| Berlin | 20 |
| Frankfurt | 22 |
| Munich | 24 |
| Berlin | 20 |
| Hamburg | 19 |
| Munich | 18 |
| Berlin | 23 |
| Frankfurt | 26 |
| Munich | 25 |
Temperatures at different recordings will be our target for this model.
Calculate the mean value for each city:
Berlin = (20 + 20 + 23) / 3 = 21
Frankfurt = (20 + 26) / 2 = 23
Munich = (24 + 18 + 25) / 3 = 22.3
Hamburg = 19 / 1 = 19
The new calculated mean values are used as a feature for training the model.
New dataset:
| city name | temperature (Y) |
|---|---|
| 21 | 20 |
| 23 | 22 |
| 22.3 | 24 |
| 21 | 20 |
| 19 | 19 |
| 22.3 | 18 |
| 21 | 23 |
| 23 | 26 |
| 22.3 | 25 |
Now the model can be trained with numerical features.
How target encoding affects ML model prediction results
We will use a very simple data set to understand exactly how target encoding affects the ML model training. For training we will use XGBoost but this is not relevant for current analysis.
For validating the model we will use the same data that we used for training. We will do it like this intentionally, to see in which cases the ML will loose information when using target encoding and how it will affect the results.
In a real use case, the dataset for ML should be used by splitting it in train, validation and test parts.
Training features:
restaurantId: the unique id of the restaurant. Could also be a unique name.
menu_items: the number of items that were ordered from the restaurant's menu
bill: the const of the order
Here is the dataset we will work with:
| # | restaurantId | menu_items | bill |
|---|---|---|---|
| 0 | 1001 | 3 | 50 |
| 1 | 1001 | 2 | 30 |
| 2 | 1001 | 1 | 10 |
| 3 | 1002 | 1 | 15 |
| 4 | 1003 | 2 | 25 |
Example 1:
First let’s train a ML model using these restaurantId and menu_items fields. For restaurantId we will use the hot encoding strategy to have an accurate model to compare the other solutions to.
Training data:
| # | restaurantId | menu_items |
|---|---|---|
| 0 | 1001 | 3 |
| 1 | 1001 | 2 |
| 2 | 1001 | 1 |
| 3 | 1002 | 1 |
| 4 | 1003 | 2 |
Y:
| # | bill |
|---|---|
| 0 | 50 |
| 1 | 30 |
| 2 | 10 |
| 3 | 15 |
| 4 | 25 |
After hot encoding restaurantId and training the model, we will apply the same train data to also predict the outputs. The results are very accurate compared to the real bill (Y) values.
| # | restaurantId | menu_items | bill | predicted_bill |
|---|---|---|---|---|
| 0 | 1001 | 3 | 50 | 50 |
| 1 | 1001 | 2 | 30 | 30 |
| 2 | 1001 | 1 | 10 | 10 |
| 3 | 1002 | 1 | 15 | 15 |
| 4 | 1003 | 2 | 25 | 25 |
Using hot encoding on fields like restaurantId is not feasible in production because these fields can grow indefinitely. Each new restaurantId would create a new column in the hot encoded training data. The model would become overwhelmed.
Example 2:
Let’s use the same dataset but instead of using restaurantId directly, we will do target encoding on the bill by adding a new column called mean_bill and calculate the mean bill value for each restaurant.
| # | restaurantId | menu_items | bill | mean_bill |
|---|---|---|---|---|
| 0 | 1001 | 3 | 50 | 30.0 |
| 1 | 1001 | 2 | 30 | 30.0 |
| 2 | 1001 | 1 | 10 | 30.0 |
| 3 | 1002 | 1 | 15 | 15.0 |
| 4 | 1003 | 2 | 25 | 25.0 |
We will train only with the following fields:
| # | menu_items | mean_bill |
|---|---|---|
| 0 | 3 | 30.0 |
| 1 | 2 | 30.0 |
| 2 | 1 | 30.0 |
| 3 | 1 | 15.0 |
| 4 | 2 | 25.0 |
And same Y:
| # | bill |
|---|---|
| 0 | 50 |
| 1 | 30 |
| 2 | 10 |
| 3 | 15 |
| 4 | 25 |
After applying this data to the same ML training logic, here are the results. Comparing bill with the model predicted_bill we get very accurate results again.
| # | restaurantId | menu_items | bill | mean_bill | predicted_bill |
|---|---|---|---|---|---|
| 0 | 1001 | 3 | 50 | 30.0 | 50 |
| 1 | 1001 | 2 | 30 | 30.0 | 30 |
| 2 | 1001 | 1 | 10 | 30.0 | 10 |
| 3 | 1002 | 1 | 15 | 15.0 | 15 |
| 4 | 1003 | 2 | 25 | 25.0 | 25 |
The high accuracy is the result of having the combination of menu_items and mean_bill always unique. In a big dataset this is hardly the case, let’s see next how duplicated encoded values can affect the outcome.
Example 3:
Target encoding works by reducing the number of variations of a field (restaurantId) and grouping fields that have a value in common (mean_bill). This means that the ML model will have less information in the training data. It will loose the uniqueness of restaurantId and would result in duplicated encoded values. This can be noticed when multiple restaurants have the same mean_bill.
Here is an example. We are adding a new row with restaurantId = 1004 that has menu_items = 1 and encoded mean_bill = 30.0, same as restaurant 1001 on row #2. Except that row #2 has bill = 10 as Y and row #5 has bill = 30 as Y.
| # | restaurantId | menu_items | bill | mean_bill |
|---|---|---|---|---|
| 0 | 1001 | 3 | 50 | 30.0 |
| 1 | 1001 | 2 | 30 | 30.0 |
| 2 | 1001 | 1 | 10 | 30.0 |
| 3 | 1002 | 1 | 15 | 15.0 |
| 4 | 1003 | 2 | 25 | 25.0 |
| 5 | 1004 | 1 | 30 | 30.0 |
So for 2 records with same menu_items = 1 and mean_bill = 30 as input, the model will be trained with bill = 10 and bill = 30 for output. Even if these bills are from separate restaurants, the model will loose this separation. So it will average it out to bill = 20.
And the results after training and predicting confirms this:
| # | restaurantId | menu_items | bill | mean_bill | predicted_bill |
|---|---|---|---|---|---|
| 0 | 1001 | 3 | 50 | 30.0 | 50 |
| 1 | 1001 | 2 | 30 | 30.0 | 30 |
| 2 | 1001 | 1 | 10 | 30.0 | 20 |
| 3 | 1002 | 1 | 15 | 15.0 | 15 |
| 4 | 1003 | 2 | 25 | 25.0 | 25 |
| 5 | 1004 | 1 | 30 | 30.0 | 20 |
Row #2 and #5 have both predicted predicted_bill = 20.
The conclusion of this research:
Categorical columns with big variations can still be useful if they are target encoded, but rows from different categories can affect each other’s results. It can be beneficial to add multiple target encoded columns to reduce the risk of duplications. Besides the mean_bill, it can also use mean_items, deviation between bill and mean_bill or any other external inputs to aggregate the rows.
Source code for this example on Github.
Code to calculate target encoding
First we create a list with all unique values in the categorical field and calculate mean value of the target_field for each key:
def get_target_encoding(df, field, target_field):
unique_fields = df[field].unique()
targets = {}
for f in unique_fields:
targets[f] = df[df[field]==f][target_field].mean()
return targets
targets = get_target_encoding(df2, 'restaurantId', 'bill')
df['mean_bill'] = df['restaurantId'].apply(lambda x: targets[x])
Adding the deviation as another target encoding column:
df['mean_bill_deviation'] = df['bill'] - df5['mean_bill']
Target encoding in a project with real data
For the Machine Learning training course offered by DataTalks.Club we had to build a full ML system by finding a dataset, perform exploratory data analysis, cleanup the features, try different ML algorithms, do hyper parameter tuning, find most accurate model, put it on a Dockerised Python server and serve it over an API. Great stuff!
I choose to predict “Berlin base rent for apartments” using a real but older dataset. You can find the entire project here: ML capstone-project
Everything went well but the accuracy was below what I expected.
Results were:
MAE: 219 euro
Model max deviation of 50euro: 27%.
Yes apartments with similar specs have rents which are deviating that much. Of course, this is just asking price, it does not mean that someone will accept it. But in Berlin, trust me, you don’t negotiate down.
Anyway, let’s see if we can improve this accuracy by applying target-encoding on a categorical column.
The cleaned up dataset looks like this:
Notice we have neighbourhood column. These are 23 neighbourhoods from Berlin and I used Hot-Encoding for this. But we also have subneighbourhood which are smaller areas of each neighbourhood. In the first training I excluded the subneighbourhood column because the dataset had 79 variations and it would make the model quite big if I would hot-encode all of them.
First we calculate the mean value for each subneighbourhood:
subneighbourhood_names = berlinDf_select['subneighbourhood'].unique() # returns 79 values
subneighbourhood_mean_baseRent = {}
for s in subneighbourhood_names :
selected = berlinDf_select[berlinDf_select['subneighbourhood']==s]
mean_baseRent = selected.baseRent.mean()
subneighbourhood_mean_baseRent[s] = int(mean_baseRent)
Then we update the dataset:
# Replacing sub-neighbourhood with mean base rent as target encoded:
berlinDf_select['subneighbourhood_meanBaseRent'] = berlinDf_select['subneighbourhood'].apply(lambda x: subneighbourhood_mean_baseRent[x])
berlinDf_select.drop('subneighbourhood', axis='columns', inplace=True)
berlinDf_select
We end up with following dataset: 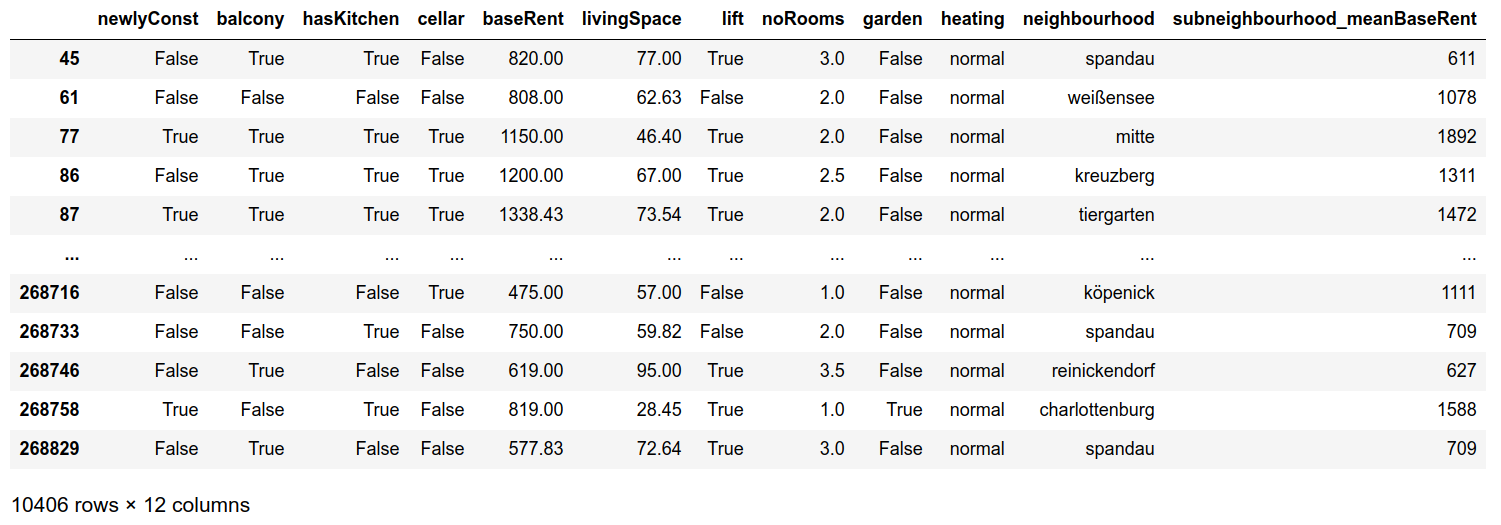
Notice Spandau has different subneighbourhood_meanBaseRent fields because it comes from different subneighbourhoods.
After applying this new dataset to same XGBoost model and perform some hyperparameter tuning we get a slight improved accuracy:
MAE: 198 euro (-21)
Model max deviation of 50euro: 26% (-1)
Source code for this project on Github.
Don’t forget, in science everything is simpler than it first seems.
Thanks for reading and happy coding!